Case study: Using data to inform business strategy
This page showcases a recent project which I completed and have published below having 1) obtained consent to do so; and 2) removed any commercially sensitive information. In this analysis I used a series of tools and methods to access, download, evaluate, clean, analyse and interpret data for a client. The project was able to successfully draw meaningful conclusions from the data set for the client.
Background
My client is a UK-based SME and is now an internationally renowned tech company. They have historically recorded their business and sales meetings and have used Fantom to transcribe meeting notes, which were saved in HubSpot. My challenge was to determine whether we could use the data to ultimately predict future staff and resource allocation, recruitment strategy and ultimately the likelihood of the deal being won or lost.
Aims
- Determine which tech stacks and skills were most discussed during sales meetings as a proxy for demand for these skills.
- Investigate skill demand over time.
- Predict deal success based on meeting transcripts.
Approach
The project was executed in two main phases: Demand forecasting (using NLP for skill extraction) and Predictive modelling (using transformer architectures for deal outcome).
Data Acquisition and Preparation
The raw data was harvested using the HubSpot API and was collected in two main tables: a Deals table (containing outcome/stage, value, and associated companies) and a Meetings table (containing the raw text transcripts, timestamps and companies involved).
- Cleaning and handling: Meeting transcripts were cleaned (tokenisation, stop-word removal, normalisation). Associated company names were standardised to enable accurate merging of meetings and final deal outcomes (whether the sale was won or lost).
- Feature engineering (demand): A custom NLP pipeline was created to identify and tag specific technical keywords (e.g., 'Flutter,' 'AWS,' 'Agile') within every meeting transcript. This allowed conversion of unstructured text into quantifiable demand metrics.
- Incorporating AI: The OpenAI API was used to ask ChatGPT to determine, from the meeting notes, whether the prospective client showed “buying intent”, which was to be used in the predictive modelling.
Analytical pipeline
| Phase | Core Technique | Output |
|---|---|---|
| Demand forecasting | Frequency analysis, time-series plotting, statistical analysis | Prioritised list of in-demand skills and a visualisation of their demand growth/decline over time. |
| Predictive modelling | Transformer fine-tuning (BERT/DeBERTa) | A classification model capable of predicting “closedwon” or “closedlost” based on meeting text and buying_intent feature. |
Key findings: Staffing & resource allocation
Analysis of the skill demand data provided clear, data-driven answers to the client's strategic staffing questions:
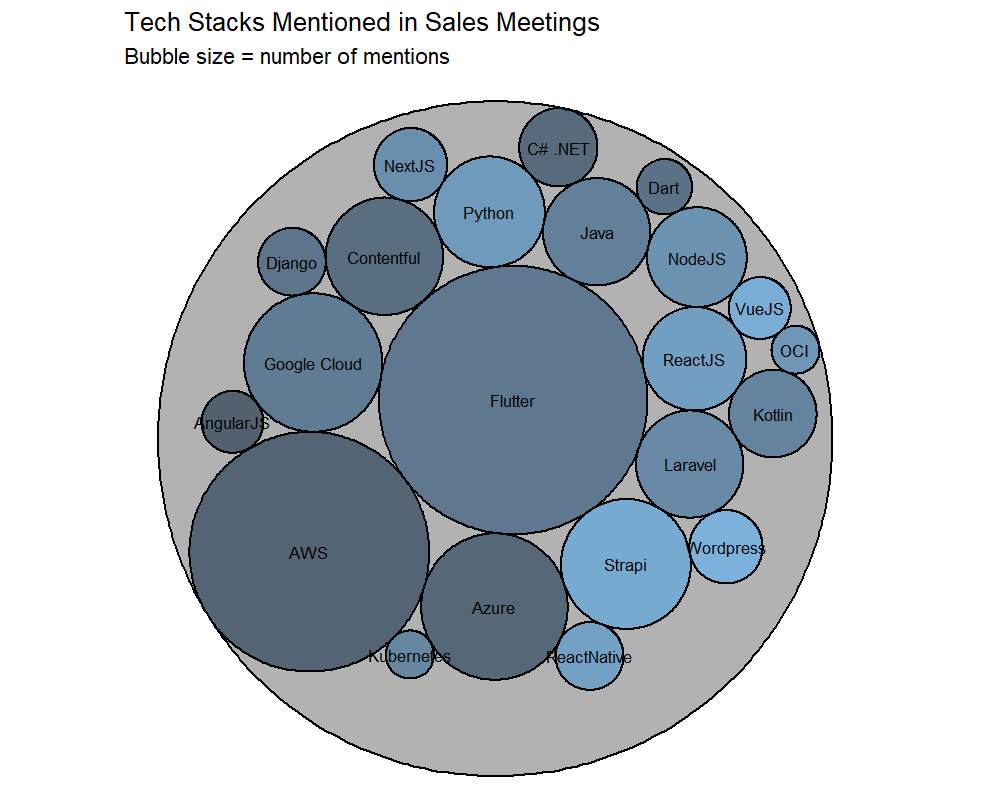
Most discussed tech stacks
The raw count of skill mentions directly correlated with immediate sales demand. By ranking the total frequency of technical keywords, we created a prioritised list for the hiring and resource allocation teams.
- Top 3 in-demand skills: Flutter, AWS and Azure.
- Top 3 in-demand skill combinations: AWS & Java, Flutter & Google Cloud Platform, AWS & Flutter.
Investigating demand over time
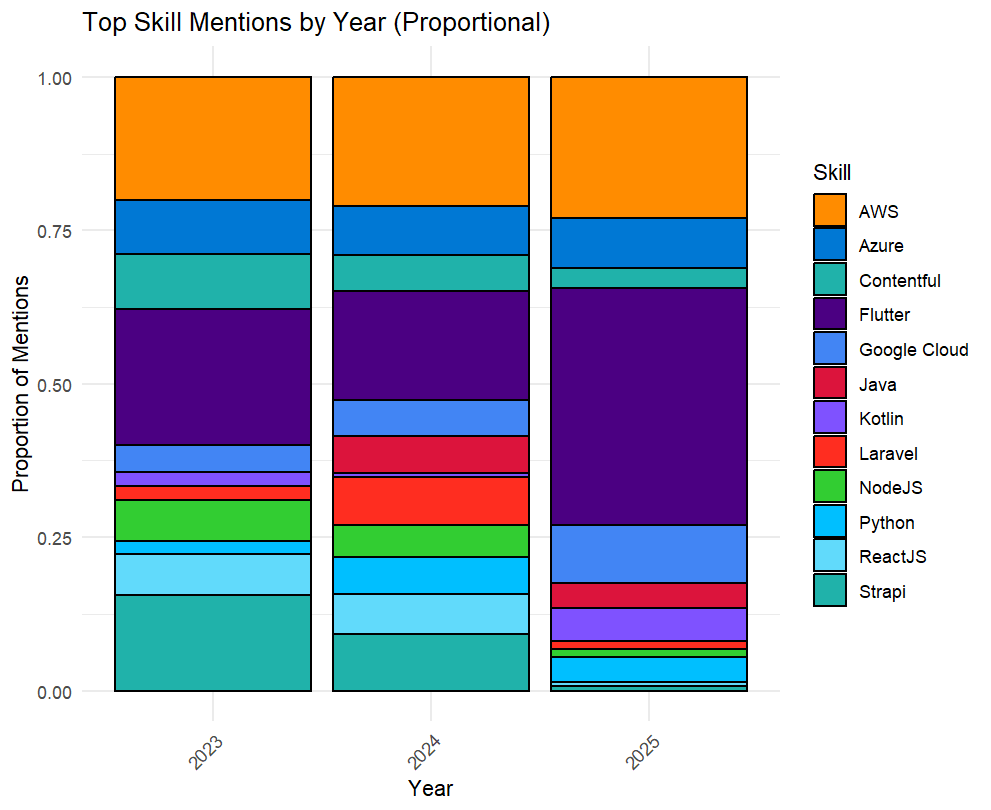
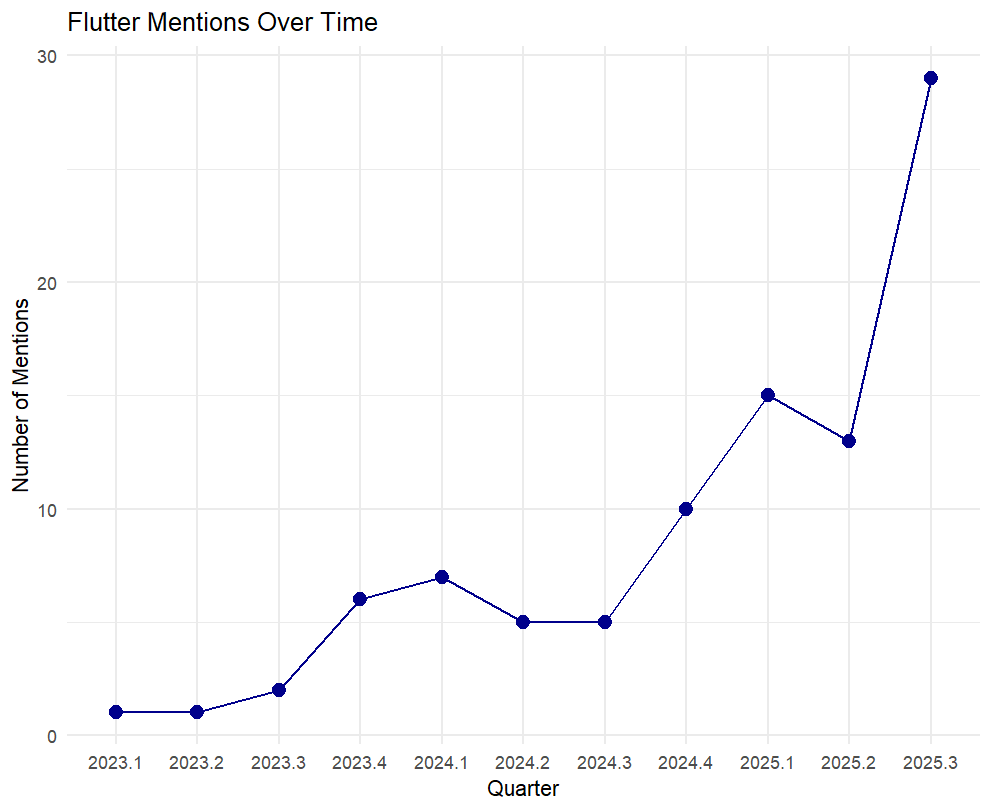
A key part of the resource strategy involved identifying not just current demand, but emerging demand. We analysed the monthly discussion frequency for the top skills.
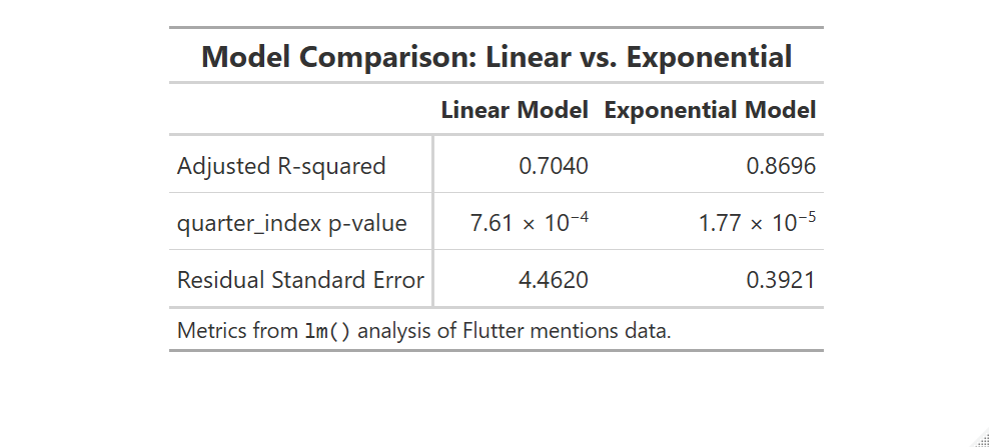
Emerging Trend: Demand for Flutter is growing exponentially, while demand for cloud platform skills (AWS and GCP) are increasing steadily.
Key findings: Deal outcome prediction
I used two alternative methods to predict the chances of a deal being won or lost based on the meeting transcripts: a fine-tuned NLP pipeline and a large language model (LLM) approach for a feature flag.
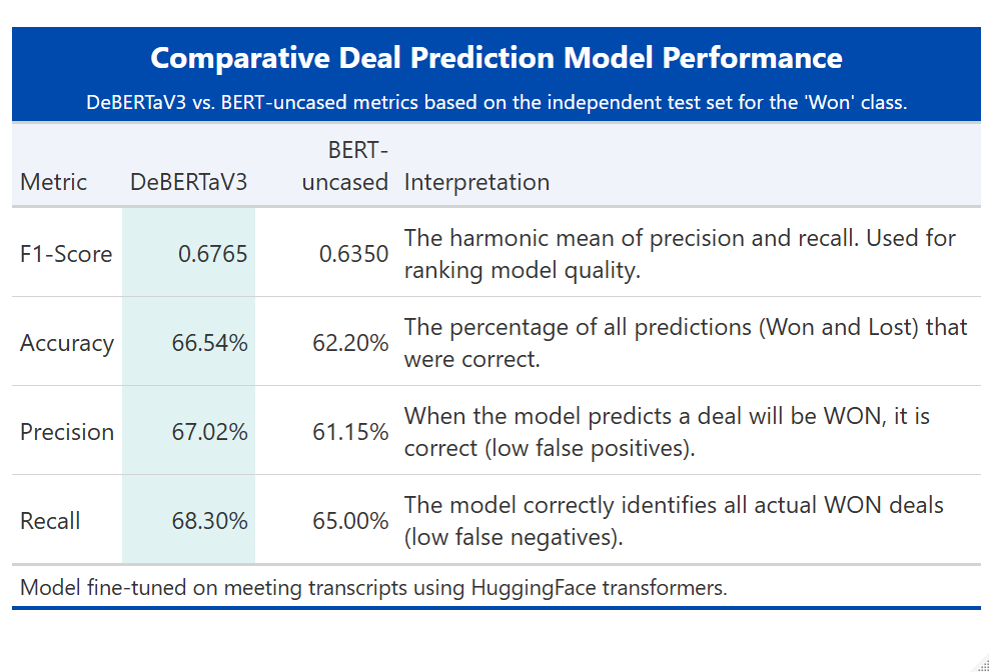
NLP model selection & performance
I fine-tuned two transformer models — BERT-base-uncased and DeBERTaV3-base. The DeBERTaV3 model provided the most reliable signal, balancing Precision and Recall effectively for production use.
ChatGPT predictive value analysis
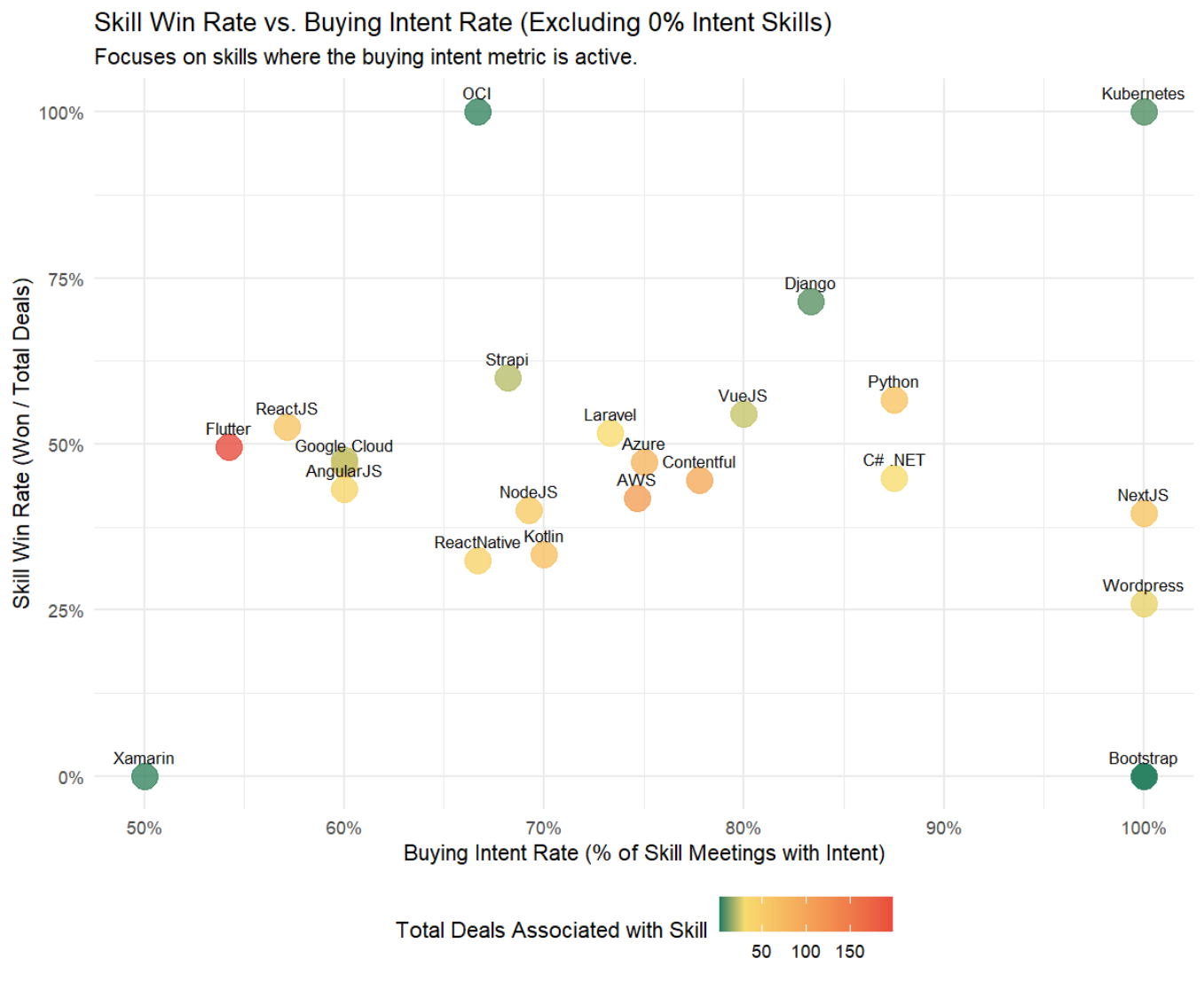
My ChatGPT-based feature performed poorly compared to the fine-tuned NLP model. Specifically, the statistical analysis showed:
- The LLM-generated buying intent metric was moderately inversely correlated with successful deal outcome (Odds Ratio 0.64, P-value 0.0005).
- This was crucial for my client, revealing that this AI-based scoring approach was flawed.
Conclusion & business impact
This project successfully translated thousands of pages of unstructured meeting data into clear, executable business strategies:
- Recruitment & resource allocation: The client could align recruitment strategy with skill demand. Identifying exponential growth (e.g., Flutter) allowed for proactive capacity building.
- Sales forecasting: The predictive model provided an objective forecasting tool. Using DeBERTaV3’s precision, my client can now prioritise deals likely to close, influencing sales approach.
The analysis provided both a view of future demand and a tool for sales pipeline management.
Methods
This project required a combination of programming, data manipulation, and advanced machine learning techniques. The overall project was executed in two main phases: Demand forecasting (using NLP for skill extraction) and Predictive modelling (using transformer architectures for deal outcome).
1. Data processing and core analytics (R & Python)
Languages: Python (primary for ML/NLP), R (primary for statistical analysis and visualisation).
Libraries (R): Tidyverse (dplyr, ggplot2), gt (for generating publication-quality tables), scales (for percentage formatting), xml2, openai, jsonlite, httr.
Libraries (Python): PyTorch, Pandas, NumPy, Scikit-learn (for classical ML/metrics).
2. Natural language processing (NLP) & feature engineering
Core NLP skill: Custom pipeline development for keyword extraction and frequency analysis.
Transformer Llbraries: HuggingFace Transformers (for fine-tuning BERT-base-uncased and DeBERTaV3-base models).
Model selection: Fine-tuning on proprietary meeting transcript data for binary classification (Won/Lost).
3. Data integration & reporting
Data sources: HubSpot API (for deal data and transcripts).
Feature enrichment: Integration with OpenAI API (ChatGPT) to generate the "buying intent" feature, which was subsequently evaluated for predictive value.
Visualisation & presentation: ggplot2 (final time-series and relationship plots), matplotlib, HTML/Bootstrap (final case study presentation).